1. 지도학습의 데이터 (Supervised Machine Learning - Data)
데이터는 머신 러닝에서 가장 중요한 요소입니다. 데이터는 숫자, 이미지, 테이블, 혹은 이미지나 영상의 형태로 다양한 형태를 띌 수 있습니다. 우리는 서로 연관성이 있는 데이터를 데이터셋 (Dataset)에 저장합니다.
데이터셋이란? (Dataset)
데이터셋은 인공지능 모델을 훈련, 검증 및 테스트하는 데 사용되는 구조화된 데이터의 집합입니다. 데이터셋은 특성 (feature)과 레이블 (label)로 이루어진 개별적 예시 (examples)들로 구성되어있습니다.
특성은 머신 러닝 모델이 레이블을 예측할 때 활용하는 정보값입니다. 레이블은 모델이 예측하기를 바라는 "정답 (answer)"입니다. 비의 양을 레이블로 예측하는 기후모델에서 특성은 온도, 습도, 풍향이 될 수 있습니다.
데이터셋의 특징 (Dataset Characteristics)
데이터셋의 주요한 특징으로는 크기 (Size)와 다양성 (Diversity), 그리고 특성 (Feature)의 수가 있습니다. 다양성은 데이터셋이 갖고 있는 예시들의 범위가 얼마나 넓은지를 측정하고, 크기는 데이터셋에 포함된 예시의 수를 의미합니다. 데이터셋의 크기가 클수록, 그리고 다양성이 높을 수록 모델 훈련에 용이합니다.
반면, 특성이 많을수록 반드시 좋은 데이터셋이라고 할 수는 없습니다. 모든 데이터의 특성이 레이블 (정답)에 대한 예측력이 있지는 않기 때문입니다. 쉬운말로,데이터 특성이 모두 레이블과 인과관계 (Causal Relationship) 에 있지 않기 때문에 특성이 많을수록 예측력이 높아진다고 볼 수 없습니다.
레이블이 있는 훈련 세트 vs 레이블이 없는 훈련 세트 (Unlabeled Example vs Labeled Examples)
특성과 레이블이 모두 포함되어 있는 예시들을 "레이블이 있는 훈려세트", 레이블이 없고 특성만 있는 예시들을 "레이블이 없는 훈련 세트"라고 명명합니다. 레이블이 없는 훈련세트의 경우, 모델이 특성을 기반으로 레이블을 예측합니다.


2. 지도학습 모델의 훈련 (Supervised Machine Learning - Model & Training)
지도학습의 모델 (Model)
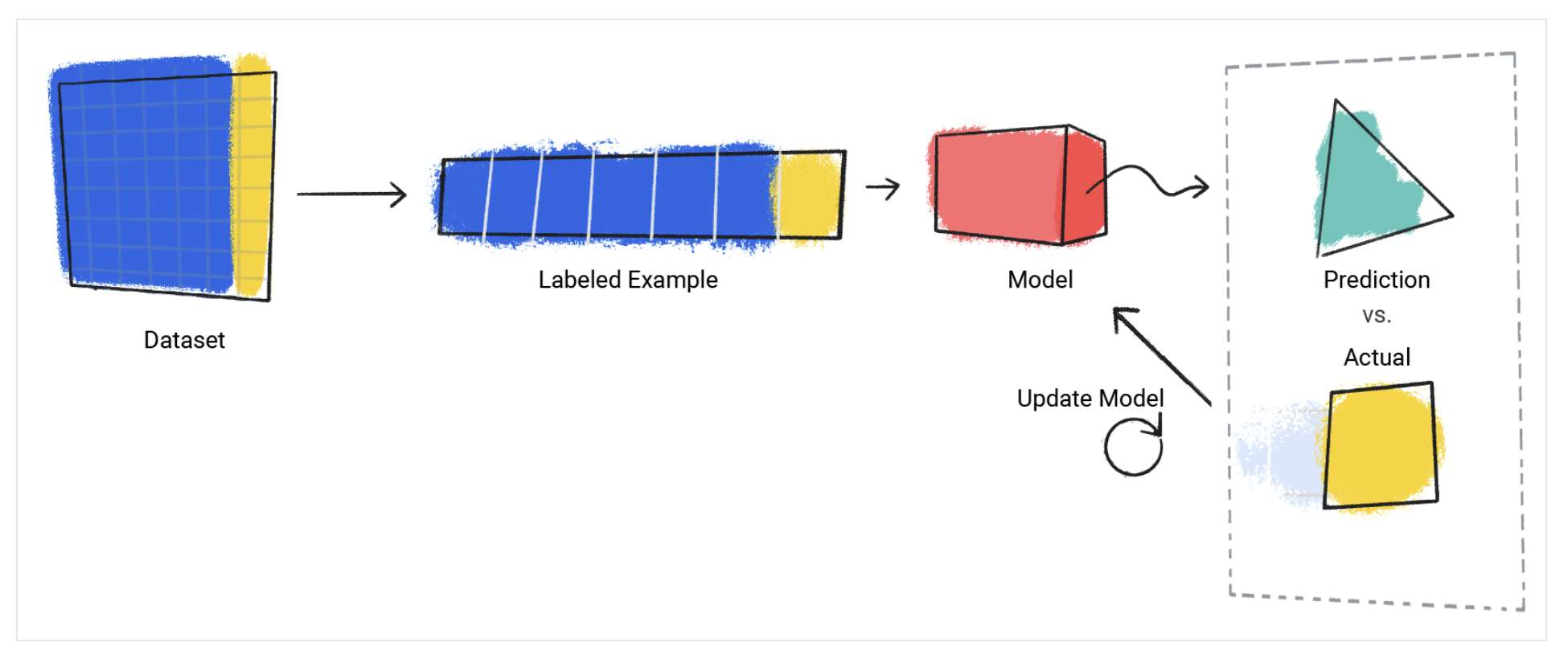
지도 학습 모델은 레이블(정답)이 있는 학습 데이터를 사용하여 입력과 출력 간의 관계를 학습하는 머신러닝 기술입니다. 모델은 훈련을 통해 특성 (Feature)와 레이블 (Label) 사이의 패턴을 발견합니다.
지도학습 모델의 훈련 (Training)
모델이 예측을 하기 위해서는 훈련 (training)을 거쳐야합니다. 지도 학습 모델을 만들기 위해 우리는 특성과 정답이 모두 있는 예시를 제공합니다. 모델의 목표는 주어진 특성을 기반으로 최적의 정답을 예측하는 것입니다. 모델이 예측한 값 (Predictive Values)과 실제 정답 (Actual Values)의 차이를 우리는 'Loss'라고 부릅니다. 모델은 Loss의 크기를 줄여가며 고도화됩니다. 요약하자면, 학습 중 모델의 알고리즘은 대규모 데이터 세트에서 잠재적 상관관계 (Mathematical Relationship)을 발견하고, 테스트 데이터의 특성을 기반으로 최선의 정답값을 예측합니다.
출처
- https://www.ibm.com/kr-ko/think/topics/supervised-learning
- https://developers.google.com/machine-learning/intro-to-ml/supervised
지도 학습 | Machine Learning | Google for Developers
이 페이지는 Cloud Translation API를 통해 번역되었습니다. 의견 보내기 지도 학습 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. 지도 학습의 태스크는 잘 정의
developers.google.com
'Machine Learning (인공지능) > 기초' 카테고리의 다른 글
| [ML] Vectorization (벡터화) (0) | 2025.10.10 |
|---|---|
| [ML] Unsupervised Learning (비지도 학습)의 정의와 종류 (0) | 2025.10.05 |
| [ML] 지도 학습 (Supervised Learning)의 정의와 종류 (0) | 2025.10.04 |
| [ML] 머신러닝 시스템의 구분 (0) | 2025.10.04 |
| [ML] 머신러닝 (Machine Learning)의 정의 (0) | 2025.10.04 |



